1
引言:从观看照片到图像先被机器读取
摄影理论常以一个基本场景作为论述起点:照片先出现,人随后观看,意义在停留、回看与解释之中逐步生成。无论是瓦尔特·本雅明(Walter Benjamin)对机械复制时代“灵光”变化的讨论,苏珊·桑塔格(Susan Sontag)对摄影目光的伦理批判,还是罗兰·巴特(Roland Barthes)关于“刺点”与私人经验的细读,都把人的观看置于解释链条的前端[1-3]。
今天,这个起点仍然有效,却不足以描述我们与照片相遇的实际路径。很多时候,我们不是先“看见一张照片”,而是先被系统带着去“找一类照片”。例如,在手机相册里输入“日落”,系统会把它认为符合“日落”特征的影像自动汇拢;在社交平台上,一张照片是否能被更多人看到,往往取决于平台在后台对其内容的识别与排序。换句话说,图像在抵达人的视网膜之前,通常已经历切分、识别、生成描述与分发决策等一系列计算步骤。
本文将这种转变概括为“摄影语义化”。这里的“语义化”并不是把照片简单“写成一句话”,而是把照片转译为可比较、可检索的表征:标签(如“海边”“婚礼”)、自动生成的图像描述,以及用于计算相似度的向量表示。可以用一个通俗的比喻来理解向量:系统为每张照片在一张“语义地图”上标一个坐标,坐标越近,照片在系统眼中就越“相似”,越容易在检索、推荐与生成的回路中彼此召回。摄影图像因此逐步从“供人观看的单张作品”变成“可被调用的语义对象”。
这一变化之所以是摄影研究的问题,原因不在技术细节,而在于它重写了可见性与解释权的分配。拍摄者开始预判平台更容易识别什么;观者逐渐习惯用关键词与问题去调度图像;平台则通过识别与排序,把“哪些照片值得被看见”先在数据库内部做出判断。丹尼尔·帕尔默(Daniel Palmer)指出,在软件与网络组织的环境中,单张照片常被纳入聚合、标注与再组织的流程,其意义与功能越来越依赖这种基础设施化的处理[4,5]。
基于此,本文围绕四个问题展开:第一,图像如何从具有多义性的视觉对象转变为机器可读、可排序的语义对象;第二,检索与提示词如何把观看改写为以提问、概括与调用为核心的“查询式观看”;第三,生成模型如何改变摄影与时间、现实与痕迹之间的关系,使纪实语法与证据感不再能由外观自动担保;第四,在语义化持续扩张的条件下,误识、盲区以及视触觉等身体化经验如何提示我们仍存在难以被完全归档的感知剩余。本文的基本判断是:当语义化成为基础设施,摄影的可见性、观看与记忆往往首先在机器内部被组织,而作者与观者的主动性也需要在这一新条件下被重新理解与重新分配。
2
从图像多义性到机器可读性:锚定的基础设施化
罗兰·巴特(Roland Barthes)在《图像—音乐—文本》中将图像描述为天然多义的符号:同一幅画面可以被读出不同甚至相互矛盾的意义,解释在多个可能路径之间滑动。为了让传播不至于在多义性中失速,大众媒体往往用标题、图注等语言把观看“拴”到某条可理解的路线,这就是巴特所谓的“锚定”(anchorage)[6]。一个直观的例子是:同样是一张街头人群与警察对峙的照片,若图注写作“骚乱现场”,读者更容易把画面理解为威胁;若写作“抗议现场”,画面又可能被理解为权利表达。锚定并不消灭多义性,却会把某一种读法变成更容易被默认的读法。
在传统媒体中,锚定大多发生在台前:标题与图注可见、可争辩,编辑选择也相对明确。平台化与人工智能深度介入之后,锚定并未消失,而是更常转入后台流程:图像先被系统自动识别、标注与归类,再被纳入聚类、检索与排序。用户在信息流里先看到什么、搜索时先出现哪些结果、平台用哪几个词概括一张图,往往不是在观看时才生成,而是在数据库内部就已被预先安排。锚定从“贴在图像旁边的文字”,转变为“写进基础设施的规则”。
要让这套规则运转,图像必须先被翻译成可计算的形式。视觉—语言模型(VLM)通常把图像与文字都编码成向量。向量可以理解为一张“索引卡”或一串“条形码”:它不是对图像的完整解释,而是一种便于比较的摘要表示。有了这种表示,系统就能高效完成两类任务:检索(把与“海边日落”“猫”“婚礼”等描述更接近的照片找出来)与排序(在同一批候选里,把更“像”查询词或更符合平台目标的结果排到前面)。因此,一张照片进入系统后首先面对的往往不是“它意味着什么”,而是“它在语义空间里离哪些词更近、应该排在第几位”。
对比式图文预训练模型(CLIP;Contrastive Language--Image Pretraining)是这一思路的代表。它并不直接处理照片的社会语境,而是把训练设为一个大规模的匹配与排序任务:在许多候选描述中,找出最可能对应这张图的那句,并让匹配的图文在向量空间里更接近[7]。这种训练常通过对比学习目标(如 InfoNCE)实现,其直观含义可以概括为“拉近正确配对、推远错误配对”[8]。在这样的目标下,模型更擅长把图像压缩为可命名的共性特征:可识别的主体、典型的动作、常见的场景。它擅长回答“这张图像最像哪个描述”,却不保证覆盖图像经验中所有难以言说、难以命名的部分。
锚定因此获得了新的落点:它不一定表现为一行写在照片旁边的文字,而更可能表现为图像在相似度、类别与排序中的“位置”和“分数”。位置一旦确立,平台便会优先放大那些高置信度、可概括、可调用的特征,并在检索、推荐与自动摘要中反复强化它们。相反,模糊、暧昧、私人联想与历史余韵并不会消失,但它们更容易被压到低置信度、难以归类的区域,难以稳定地被系统召回。为了在这样的可见性机制中被“找到”,图像生产也会被反向塑形:主体更突出,画面更像一句关键词,风格更易归类。帕尔默所说的“冗余照片”在此呈现出新的技术含义:单张照片的独立性让位于其作为数据样本、元数据节点与可计算条目的功能[4,5]。
更重要的是,锚定一旦被基础设施化,它就会把既有的分类学与偏见一并带入视觉判断。凯特·克劳福德(Kate Crawford)与特雷弗·帕格伦(Trevor Paglen)的《图像网轮盘》(ImageNet Roulette)展示了这种社会后果:当系统依赖既有数据集与标签体系对人像进行分类时,某些带有阶层、性别或种族色彩的词会以“技术标签”的形式被输出,并在界面上获得一种似乎中立的权威感[9]。在这里,需要被讨论的不仅是“标签对不对”,还包括:这些标签从何而来,哪些类别被当作常识被固化,哪些群体更容易被误识,以及这种误识将如何影响可见性、信誉与风险分配。

因此,“标签的暴力”并不只指少数极端的误判,而指一种日常化的过滤机制:系统优先抽取并放大易于命名、易于对齐、易于检索的部分,使图像先以“可计算的摘要”进入流通。图像并没有停止生产意义,但哪些意义能被承认、被分发、被召回,往往要先过这道筛。摄影的多义性依然在,只是它越来越常先被整理成机器容易处理的形状,然后才进入可见与可流通的路径。
这就是锚定的基础设施化:解释不再主要附着在图像旁边,而是被写进向量空间与排序规则里,先决定什么更可能被看见、被怎样描述。锚定一旦以排序与检索的形式存在,前台的观看也就更容易被改写为提问、筛选与调用的过程。
3
查询式观看与注意力的重组
上一节讨论的图文对齐与排序,主要发生在后台:图像被编入一张可检索、可比较的语义关系网。多模态对话把这一能力推到前台,使观看越来越常以“提问”的方式展开。在支持图片输入的对话式人工智能界面(AI)中,用户把一张图发出去,接着追问“这是什么”“帮我提取关键词”“这张照片有没有隐私风险”“给我一段发布文案”,已经成为日常操作。图像在这里不再只是等待凝视与解释的对象,更像一个入口:围绕同一张图,用户持续提出问题、生成摘要、改写描述,并把结果直接接到搜索、写作、生成与决策的下一步。
本文将这种以提问与提示词为入口、以可复用的文本结论为主要产出的观看方式,称为“查询式观看”。它的关键特征在于“问题先行”:观看不以停留与回看为起点,而以一个明确任务为起点——识别、概括、比较、筛选、评估风险或生成可发布的表述。图像因此更像被“处理”的材料,而观看更像一套可交办的工作流。
从系统结构看,多模态对话通常要经过一条转换链:图像先被视觉编码器压缩成特征表示,再通过连接模块送进语言模型,使视觉信息能够作为对话上下文参与推理与生成。经过指令微调后,系统能做的就不止是判断图文是否匹配,而是围绕对象、场景、文字、关系与任务目标生成回答、摘要或操作建议[10]。可以用更通俗的方式理解这条链:系统先把画面“记成一份摘要”,再按你的问题把摘要“翻译成一句可用的话”。同一张照片在不同问题下会被组织成不同的摘要:问“画面里有哪些物体”会凸显可命名的主体;问“这张图适不适合发朋友圈”则会优先触发对人脸、位置与敏感信息的提取。提示词在这里不仅是提问,也是筛选器。
因此,查询式观看并不是简单地“更快看图”,而是改变了注意力的分配方式。传统观看允许意义在游移中生成:观者可以停在一个细节上反复端详,也可以把不确定留在画面里。查询式观看更像先设定输出,再从图像中抽取可陈述、可转写、可调用的部分。那些难以命名、难以压缩成一句话的细节——例如边缘处的光线起伏、微妙的表情、暧昧的关系张力——并不会消失,但更容易在“答案优先”的结构里被归为背景或噪声。换言之,观看在形式上仍发生,但它更频繁地被改写为“获取可用结论”的过程。
慢观看当然没有消失,但在主流数字界面中的位置被挤压了。平台通过搜索、推荐、聚类与自动摘要来组织图像,使“看”越来越像“找”,也越来越像“调用”。帕尔默在讨论图片分享平台(Flickr)与照片聚合项目(Photosynth)等实践时指出,软件通过元数据与算法排序重写照片的价值与可见性;照片越能被索引、被聚合、被再组织,就越容易进入新的流通路径[4,5]。希托·施泰耶尔(Hito Steyerl)在《如何不被看见》(How Not to Be Seen)中讽刺数字可见性体制:在高分辨率与全面识别的制度里,存在感往往与“可被解析、可被索引”绑定在一起[11]。不可计量的部分未必立刻消失,却更容易滑向系统的低权重区域。

对摄影而言,查询式观看带来的结构性变化主要体现在三个层面。第一,语境更容易被后置:拍摄情境、媒介物质性、展示方式与历史位置,往往要等到“答案”生成之后才被补回;在多数界面里,观者先接触到的是主体识别、风格匹配与摘要式描述。第二,记忆路径被改写:回忆不再主要依赖偶然触发,而更依赖搜索词、时间线、地理位置与相似图像的推荐链;“想起一张照片”越来越像“检索一条结果”。第三,作者性出现微妙位移:摄影师不再只是在现场捕捉瞬间,也会在拍摄与发布阶段预设后续检索、编辑与再利用所需的线索——从标题、标签到可被模型稳定识别的主体与风格。拍摄与元数据生产之间的边界因此变得模糊。
这种观看方式会进一步反向塑形图像生产。为了被识别、被归类、被推荐,图像更倾向于呈现“更好描述”的形式:主体更突出,构图更标准,风格更稳定,画面更像一条能被一句话概括的关键词。社交平台上视觉风格的快速标准化,不仅来自审美模仿,也来自对排序与检索机制的适配。摄影当然仍在,但它越来越像被嵌进一条计算优先的分发链条:先被系统处理,再被人看见。也正是在这条链条上,描述开始从“概括照片”滑向“生成指令”,从而把观看与生产更紧密地连在一起,为下一节关于生成模型的讨论奠定条件。
4
从痕迹到概率:生成模型如何改写摄影时间观
摄影在现代视觉文化中之所以具有特殊的认识论地位,一个核心原因在于它与“曾经在那里”的物理关联。无论是新闻纪实、监控截图还是私人照片,人们之所以愿意把照片当作证据或记忆的触发器,通常是因为它被理解为某一时刻的光学痕迹:快门把连续的事件时间切成一个可回看的切片。巴特在《明室》中反复追问的“此曾在”(that-has-been),正是建立在这条痕迹链条之上[3]。亨利·卡蒂埃-布列松(Henri Cartier-Bresson)关于“决定性瞬间”的叙述同样依赖这一前提:摄影师在场,现实在流动,关键动作与形式结构在同一瞬间被封存[12]。
生成式模型改变的,正是照片与事件时间之间这种默认的绑定关系。以扩散模型为例,它并不从外部现实中截取一个时刻,而是在训练中学习如何把随机噪声一步步还原为“看起来像某类图像”的结果;在生成时,它在提示词的约束下从噪声出发,通过多轮去噪迭代逼近一张可读的画面。潜扩散模型(latent diffusion model, LDM)把去噪过程放在压缩后的潜表示中运行,从而以较低的计算成本生成高分辨率图像[13]。对读者而言,一个直观的判断是:当你输入“生成一张像 1950 年代街头抓拍的黑白照片”这样的提示词时,系统并不是回到某个 1950 年代的现场取证,而是在它学到的统计规律上合成一个“符合描述”的样本。提示词因此不再只是对图像的事后描述,而成为图像生成的条件。
由此,图像的时间性被重新组织。摄影对应的是事件时间:快门指向一个已经发生的瞬间,所谓“错过”往往意味着不可逆的损失。生成图像当然也有时间,但它更像制作时间:去噪迭代走了多少步,提示词改了多少轮,候选结果被放弃与重来的次数有多少。若要用摄影内部的类比来说明:暗房里可以反复试印,但底片仍来自现场;而生成则把“反复试”的部分前置为主要过程,图像从一开始就以可重来为前提。偶然性并未消失,但它更多来自参数、采样与选择,而不是来自世界本身的偶发瞬间。
马里奥·克林格曼(Mario Klingemann)的装置《过路人记忆 I》(Memories of Passersby I)把这种时间观的转移变得可见。装置持续生成从未存在过的人脸,画面不断刷新,没有哪一帧对应一个可追溯的过去,也很难指定某个时刻为唯一的“真实瞬间”[14]。作品呈现的不是被封存的过去,而是模型不断输出的现在:图像的“在场”来自演算过程,而非来自现场痕迹。

如果说克林格曼突出的是“持续输出”,那么MT的《老老实实拍照》(The Honest Photographer)则把同样的问题放回摄影最熟悉的语法:一张看似带有“决定性瞬间”气息的街头照片。项目先生成一张拟卡蒂埃-布列松风格的静帧,再围绕它生成多个版本的故事文本与对话式评论,并进一步用视频模型把画面沿时间轴向前、向后延展出不同版本[15]。静帧因此不再只是结论,而成为一个可被反复补写的起点:它被写成故事、写成评论,再被写成前后的影像片段。
在这一结构中,“决定性”从快门时刻转移到版本选择。生成会提供多张候选画面、多条叙事、多段延展,作品最终必须做出取舍——挑哪一张、采用哪条叙事、保留哪段时间延展。选定哪一帧,作品就把它当作“瞬间”;选定哪段延展,这张静帧就被放进相应的前后关系里。更关键的是,项目把人机对话与制作材料一并呈现,使这些选择不再隐藏在后台,而成为可被观看与讨论的部分。在这里,作者性更多体现为“版本管理与选择”,而不是单次在场捕捉。
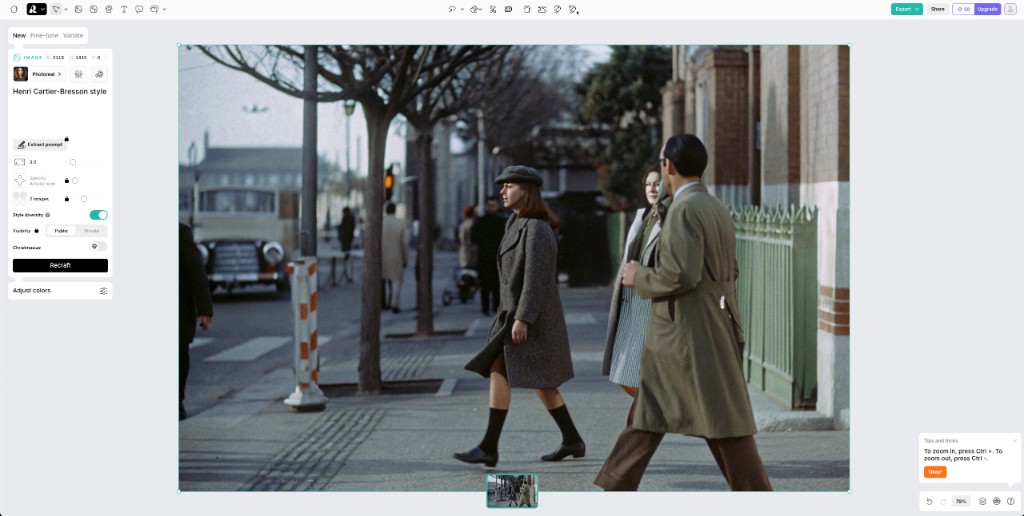

将这两类实践并置,它们共同指向一个更广泛的后果:照片的外观越来越难以自动担保那条“现场痕迹”的关系。看起来像纪实的画面可能来自合成;实拍底片也可能在后期被生成逻辑补写与延展,而这些差异在界面上往往并不显眼。问题因此不止落在“真不真”,而更具体地落在生产链条与责任分配:图像的时间感来自哪一次事件,还是来自哪一次采样?它的证据感由哪些机制担保?作者、平台、模型与观者分别在何处介入,又在何处承担责任?同一张图像越是可以被语言描述、被提示词改写、被模型反复调用,所谓“摄影”的边界就越不再只由光学现场来划定。如果说生成让“痕迹”变得不可靠,那么语义化体制里的另一个同样关键的问题就是:机器在何处看错、看漏,这些盲区又如何被反向利用。
5
误识、盲区与可见性的反向利用
上一节指出,生成模型使“痕迹”不再可靠;同样重要的是,语义化系统并不总能稳定地“看对”。摄影语义化看上去是一套不断扩张的收编机制,却并非无懈可击。系统越依赖统计常态,越容易在异常、模糊与边界案例面前失准。日常讨论常把这类失准统称为“机器幻觉”,但在分析层面,更有必要区分其中不同的机制,因为它们对应不同的技术前提、社会后果与可见性政治。
本文将相关失准粗略分为三类。第一类是识别错误(misrecognition):系统把图像错归到某个类别,或把某个类别过度泛化到不适合的对象上。这类错误常发生在图像信息不足(遮挡、低分辨率、强反光)或类别边界本就模糊(“危险”“可疑”“不雅”等价值负载标签)的情境中,后果往往体现为错配的标签、错误的排序与不可预测的可见性惩罚。第二类是对抗性误导(adversarial misdirection):输入并未改变人的直观判断,但某些微小扰动会让模型的决策大幅偏转。它提醒我们,所谓“可见”并非单纯来自画面内容,而来自模型如何在特定表征空间里读入并计算。第三类是生成式补全(generative confabulation):在信息不足或不确定时,系统仍倾向于给出连贯答案,把“可能的细节”当作“确定的事实”。在图像描述、问答与摘要成为常用界面功能后,这类补全尤其值得警惕,因为它会把不确定性伪装成确定性,并以文字的形式进入传播与决策。
申承帛与金容勋(Shinseungback Kimyonghun)的《云脸》(Cloud Face)把识别错误背后的“分类惯性”展示得很直观。作品把人脸识别系统对准云层,机器便在无定形的纹理里不断“发现”脸[16]。这种误识并不只是偶然的失手,而是暴露出一种急切的命名冲动:当系统被设计为必须输出“是什么”时,它往往宁可在混沌中误判,也要把流动形态塞进已准备好的类别模板。换句话说,机器的“看见”并不等同于中立的记录,而是一种被类别库与阈值策略预先塑形的判断。

当我们把目光从“误识”转向“盲区”,问题会更具体。盲区并不只是系统“看不到”,而是系统在何种条件下选择不看、不会看或不愿承认自己没看清:哪些输入被标为低置信度、异常值或噪声,哪些对象缺乏可用标签而被排除在检索与推荐之外,哪些语境信息(拍摄关系、权力关系、情感氛围)在表征转换中被默认无关。盲区因此是一种结构性产物:它来自分类体系的覆盖范围、训练样本的分布、以及平台对“可用输出”的硬性要求。
盲区也为艺术与批判实践提供了一种反向入口。模糊、遮蔽、叠加、反常构图与风格化处理等策略,并不只是把图像“做得更难识别”,而是在迫使系统暴露其边界与偏好:它依赖哪些标准化样本,惩罚哪些不可归类之物,又如何在效率与准确性的名义下缩窄可见性的范围。需要强调的是,这类裂缝既可能成为批判的入口,也可能制造新的排斥与伤害;因此“反向利用”并非简单的胜利叙事,而是一种必须被审慎讨论的实践条件。
总体而言,盲区提醒我们:语义化并不能覆盖全部经验,机器可见性也不等于视觉经验本身。摄影语义化越推进,越需要关注那些在系统中被标成噪声、低置信度与无效信息的部分。它们未必只是残余,有时反而是理解图像政治与可见性制度的入口。不过,摄影的“剩余”并不只存在于系统失准之处,它也来自观看的身体与经验本身。下一节将转向这一更难被语义化的层面。
6
语言之外的剩余:视触觉与身体化观看
上一节把误识与盲区当作入口,说明语义化体制并不透明。即使系统没有看错,它也往往只能给出一种可调用的摘要,难以覆盖那些先于语言、依赖身体的观看经验。语义化把图像翻译成关键词、标签与描述,使图像更易被检索与再生产;同时,一些经验也会在翻译过程中被压扁。关键问题因此转向:在语义化不断扩张的条件下,图像经验里是否仍有一些维度,总会从命名与归档中滑出去?
劳拉·马克斯(Laura U. Marks)提出“视触觉”(haptic visuality),用以描述一种贴近表面的观看方式:当颗粒、纹理、模糊、明暗与光线起伏被凸显时,目光不急着确认“这是什么”,而会在图像表面缓慢移动,仿佛在触摸材料[17,18]。在摄影经验里,这类观看常出现在低照度、失焦、压暗或颗粒粗重的影像中。系统可能把它们概括为“模糊”“噪点多”“曝光不足”,但对观者而言,这些被当作“缺陷”的部分往往正是情绪进入的通道。比如一张老家庭照边缘发灰、细节丢失,我们未必先去辨认人物身份,而可能先被时间的痕迹、纸面质地与光线的柔软感抓住。
魏王恺在讨论摄影的共情机制时强调,影像可以先于叙事发挥作用:它先把人带入一种情绪质地,再让解释慢慢补上[19]。视触觉观看恰好说明了这种“先感到、后命名”的次序。当观看以“感到”为起点时,语境并非被彻底取消,而是被延后。相较之下,自动字幕与关键词摘要更擅长把画面转换为可复用结论,它们会优先保留可命名的主体与动作,而把表面质地压缩为背景属性。于是,同一张照片在系统里越是被顺利概括,就越可能失去让人停留的那层触感。
在这个脉络里,巴特所说的“刺点”(punctum)也更容易落地。刺点不是一个稳定的对象特征,而是某个细节与观者经验发生偶然碰撞时产生的偏移[3]。它可能是一处衣领的褶皱、一只手的姿势、角落里一件不起眼的物品——在统计意义上不一定重要,却能突然把观看者拉进私人记忆。算法更擅长处理共性与高频描述,因此更容易突出“这张照片是什么类型”“有哪些对象”,却很难预先知道哪个细节会在谁的生命经验里被触发。刺点因此构成一种难以被完全语义化的剩余:它不是“信息不足”,而是意义生成依赖具体的人。
语义化已经成为图像制度的一部分,观看实践反而成了仍可被重新布置的环节。慢看、重看、错读、材料性分析、在展览空间中的身体移动、与图像表面的长时间相处,这些实践不以高效调用为目标,却能让图像经验重新获得纹理,并为共情与反思保留空间。算法可以帮助我们提取与归档,却难以替代人在不确定中逗留、被触动、再回去重看的能力。只要这种逗留仍在,摄影就不会被完全还原为标签、向量与指令。
7
结语:摄影没有终结,但它的制度已经改变
本文以“摄影语义化”概念描述一种正在成形的制度变化:摄影图像在平台与多模态模型的处理链中被预先标注、嵌入与摘要,继而在检索、推荐与生成的回路中以语义对象的形式被调用。由此,图像的可见性、可解释性与可记忆性,越来越先在机器内部被组织,而不是在观看现场才被决定。
围绕这一判断,本文从三个层面展开论证。第一,巴特关于多义性与锚定的讨论提示我们:当锚定从标题与图注转入向量空间与排序规则时,解释权的重心随之迁移[6]。第二,查询式观看将“看”改写为以提问与调用为核心的任务流程,提示词成为新的筛选框架,使图像更快地被压缩成可复用结论。第三,扩散模型等生成机制把摄影的时间逻辑从事件切片推向版本选择,使外观难以再自动担保“现场痕迹”关系[13]。
这些变化并不意味着摄影失效,而意味着其功能越来越在网络化的软件环境中被重新定义。帕尔默所说的“冗余”在此可以被理解为一种基础设施条件:单张照片的价值不再主要来自其作为孤立作品的自足性,而来自它在数据库中的可索引性、可匹配性与可复用性[4,5]。摄影因此不只是“把世界拍下来”,也越来越是在为检索、排序与生成提供可被调用的材料。
对影像人文学与摄影批评而言,这要求我们把分析单位从“作品—作者—观者”的三角关系扩展到“管线—界面—制度”。讨论一张照片,不仅要问它呈现了什么,也要问它如何被标注、如何被检索、如何被排序、如何被摘要,以及它如何进入训练与生成的回路。档案、教育与策展也需要相应更新问题意识:区分痕迹型影像与合成型影像的生产链,记录可验证的来源与处理过程,并培养对元数据与模型摘要的批判性读法。
与此同时,本文也强调语义化无法穷尽图像经验。误识与盲区揭示了分类体系的边界,而视触觉与刺点则提醒我们:观看仍包含具身的停留、偶然的触动与无法预演的意义生成[3,17,18]。在弗卢塞尔(Vilém Flusser)的装置论视角下,关键问题不在于拒绝装置,而在于理解它如何预设可能性,并在其中重新组织作者与观者的主动性[20]。
综上,摄影没有终结,但它的制度正在重组:从以光学见证为中心,转向以可计算、可检索与可调用为中心。对当代摄影的有效分析,需要同时面对这套基础设施带来的新可见性、新观看与新记忆,并为那些仍然难以被语义化的经验保留位置。
参考文献
参考文献
- [1] 本雅明, 瓦尔特. 机械复制时代的艺术作品[A]. 见: 阿伦特, 汉娜, 编. 启迪[M]. Zohn H, 译. New York: Schocken Books, 1969: 217--251.
- [2] 桑塔格, 苏珊. 论摄影[M]. New York: Farrar, Straus and Giroux, 1977.
- [3] 巴特, 罗兰. 明室: 摄影札记[M]. Howard R, 译. New York: Hill and Wang, 1980.
- [4] PALMER D. Redundant photographs: Cameras, software and human obsolescence[A]. In: RUBINSTEIN D, GOLDING J, FISHER A, eds. On the Verge of Photography: Imaging Beyond Representation[M]. Birmingham: ARTicle Press, 2013: 149--166.
- [5] 帕尔默, 丹尼尔. 冗余的照片: 相机、软件与人的过时[J]. 陈秋, 译. 中国摄影, 2026(2).
- [6] 巴特, 罗兰. 图像-音乐-文本[M]. Heath S, 译. London: Fontana Press, 1977.
- [7] RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]//Proceedings of the 38th International Conference on Machine Learning. 2021: 8748--8763.
- [8] VAN DEN OORD A, LI Y, VINYALS O. Representation learning with contrastive predictive coding[EB/OL]. arXiv, 2018. https://arxiv.org/abs/1807.03748.
- [9] CRAWFORD K, PAGLEN T. ImageNet Roulette[Z]. 2019.
- [10] LIU H, LI C, WU Q, et al. Visual instruction tuning[EB/OL]. arXiv, 2023. https://arxiv.org/abs/2304.08485.
- [11] STEYERL H. How Not to Be Seen: A Fucking Didactic Educational .MOV File[Z]. 2013.
- [12] 卡蒂埃-布列松, 亨利. 决定性瞬间[M]. New York: Simon and Schuster, 1952.
- [13] ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 10684--10695.
- [14] KLINGEMANN M. Memories of Passersby I[Z]. 2018.
- [15] MT. The Honest Photographer[Z/OL]. 2024. https://mt-zeng.com/the-honest-photographer.
- [16] SHINSEUNGBACK KIMYONGHUN. Cloud Face[Z]. 2012.
- [17] MARKS L U. Video haptics and erotics[J]. Screen, 1998, 39(4): 331--348.
- [18] MARKS L U. The Skin of the Film: Intercultural Cinema, Embodiment, and the Senses[M]. Durham: Duke University Press, 2000.
- [19] 魏王恺. 从观看到被看见: 摄影作为一种稳定的共情渠道[J]. 中国摄影, 2026(2).
- [20] 弗卢塞尔, 维莱姆. 迈向摄影哲学[M]. Mathews A, 译. London: Reaktion Books, 2000.